[인프런] 실리콘밸리 엔지니어와 함께하는 샐러리(Celery) 학습 정리 3
2024.06.29 - [Study/django] - [인프런] 실리콘밸리 엔지니어와 함께하는 샐러리(Celery) 학습 정리 1
2024.06.30 - [Study/django] - [인프런] 실리콘밸리 엔지니어와 함께하는 샐러리(Celery) 학습 정리 2
* 그동안 celery flower의 동작에 대한 근본적인 문제를 해결하지 못하던 상황에서 최종 해결책에 대해 정리를 먼저 한다.
- 문제 : docker-compose로 django, celery, flower를 동작시키면 "...inspector:44] Inspect method stats failed..." 에러가 발생하였다.
- 1차 문제 해결 방안 : runserver로 구동하면 문제가 발생하지 않았지만, gunicorn으로 구동하면 문제가 발생했다.
- 2차 문제 해결 방안 : 구체적으로 nginx가 없이 gunicorn만으로 에러가 발생한다는 것을 알게 되었다.
- 구체적인 원인 : chatgpt를 이용해 원인을 찾아보았다.
1) runserver 모드:
- Django의 runserver 모드는 개발 환경에서 사용되는 내장 웹 서버이다.
- runserver 모드에서는 Django의 django.contrib.admin 앱에 포함된 StatsDashboardView 클래스가 제공하는 API를 Celery Flower가 사용할 수 있다.
- 이 API를 통해 Celery Flower는 Django 애플리케이션의 상태 정보를 모니터링할 수 있다.
2) Gunicorn 모드:
- Gunicorn은 프로덕션 환경에서 사용되는 WSGI 서버이다.
- Gunicorn 모드에서는 Django의 django.contrib.admin 앱에 포함된 StatsDashboardView 클래스가 제공하는 API가 기본적으로 노출되지 않는다.
- 이 경우, Celery Flower가 Django 애플리케이션의 상태 정보를 모니터링하기 위해 사용하는 API에 액세스할 수 없게 되어 inspector:44] Inspect method stats failed 에러가 발생한다.
- 필요한 API:
- Celery Flower는 Django 애플리케이션의 다음과 같은 API를 사용하여 상태 정보를 모니터링한다:
1. django.contrib.admin.views.stats.StatsDashboardView: Django 관리자 페이지에서 제공하는 통계 API이다. 이 API를 통해 Celery Flower는 Django 애플리케이션의 전반적인 상태 정보를 얻을 수 있다.
2. django.contrib.admin.views.main.ModelAdmin.changelist_view: Django 관리자 페이지에서 제공하는 모델 목록 API이다. 이 API를 통해 Celery Flower는 Celery 작업의 상태 정보를 얻을 수 있다.
- runserver 모드에서는 이러한 API가 기본적으로 제공되지만, Gunicorn 모드에서는 추가적인 설정이 필요하다.
- 따라서 Gunicorn 모드에서 Celery Flower를 사용하려면, Django 애플리케이션에 이러한 API를 노출하도록 설정해야 한다. 이를 통해 Celery Flower가 Django 애플리케이션의 상태 정보를 정상적으로 모니터링할 수 있다.
1. Exception handling
1) Celery Task의 예외 처리
- 관련 페이지 : https://docs.celeryq.dev/en/stable/reference/celery.exceptions.html
- worker/celery_tasks/tasks.py에 예외 발생 코드 추가
import logging
from worker.celery import app
@app.task(queue="celery")
def my_super_task():
try:
raise IOError("File X does not exists")
except IOError as e:
logging.error(e)
- celery log
- 아래와 같이 출력이 되는 이유는 my_super_task 입장에서 except까지의 코드가 성공적으로 동작하고 return 되었기 때문이다. 만약, except가 없이 raise만 있다면 에러가 발생한다.

- raise로 에러만 발생시킨 경우 log

2) Custom Task Class
- Task inheritance :
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/tasks.html#task-inheritance
- task의 특정 작업을 오버라이딩 해야 하는 경우 아래와 같이 사용할 수 있다.
import celery
class MyTask(celery.Task):
def on_failure(self, exc, task_id, args, kwargs, einfo):
print('{0!r} failed: {1!r}'.format(task_id, exc))
@app.task(base=MyTask)
def add(x, y):
raise KeyError()
1. on_failur에 대한 오버라이딩 테스트 코드
- worker.celery_tasks.tasks의 my_super_task 수정
import logging
import time
import traceback
from celery import Task, group
from worker.celery import app
from worker.tasks import add
# @app.task(queue="celery")
# def my_super_task():
# try:
# raise IOError("File X does not exists")
# except IOError as e:
# logging.error(e)
# Define custom task class
class CustomTask(Task):
def on_failure(self, exc, task_id, args, kwargs, einfo):
# exc: The exception that caused the task to fail.
# task_id: The ID of the failed task.
# args: The arguments passed to the task.
# kwargs: The keyword arguments passed to the task.
# einfo: An object containing information about the exception.
# This method is called when a task fails
print(f"Task failed: {exc}")
# Optionally, you can perform actions like logging or sending notifications here
# For example, you might want to retry the task under certain conditions
if isinstance(exc, Exception):
logging.error(f"Error happens on {task_id}... fix this!!!")
# Register custom task class with Celery
app.task(base=CustomTask)
@app.task(
queue="celery",
base=CustomTask,
)
def my_super_task():
# try:
raise IOError("File X does not exists")
# except IOError as e:
# logging.error(e)
- 에러 로그
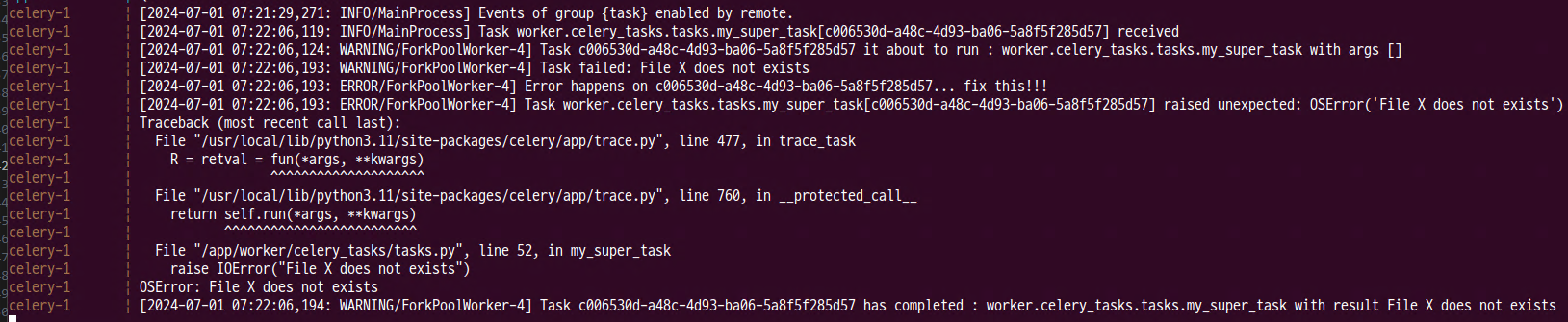
3) Task Retry 메커니즘
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/tasks.html#retrying
- 에러가 발생했을때 재실행을 설정하는 방법
- task의 파라미터로 bind=True를 설정하면 함수의 받는 인자로 self를 사용할 수 있고 이 self를 이용해 task의 모든 파라미터에 접근할 수 있다. 이를 사용한 retry 구현은 아래와 같다.
@app.task(bind=True)
def send_twitter_status(self, oauth, tweet):
try:
twitter = Twitter(oauth)
twitter.update_status(tweet)
except (Twitter.FailWhaleError, Twitter.LoginError) as exc:
raise self.retry(exc=exc)
- custom retry delay, retry를 할 때, 바로 시도를 하는게 아니라 일정 시간 지연을 시킬 수 있다.
- 데코레이터를 이용한 방법과 self.retry의 파라미터 설정을 통한 방법 2가지가 있다.
@app.task(bind=True, default_retry_delay=30 * 60) # retry in 30 minutes.
def add(self, x, y):
try:
something_raising()
except Exception as exc:
# overrides the default delay to retry after 1 minute
raise self.retry(exc=exc, countdown=60)
- 기타 추가적으로 재시도 횟수 지정, 특정 예외에서만 동작 등의 설정을 할 수 있다. 공식 문서를 확인하자.
1. 여러 데코레이터 설정을 이용한 테스트
- tasks.py 설정
@app.task(
queue="celery",
base=CustomTask,
autoretry_for=(IOError,),
max_retries=3,
default_retry_delay=10,
)
def my_super_task():
# try:
raise IOError("File X does not exists")
# except IOError as e:
# logging.error(e)
- 에러 로그 : IOerror에만 동작하며 10초마다 재시작을 실행하고 총 3회 시도 후 에러가 발생한다.
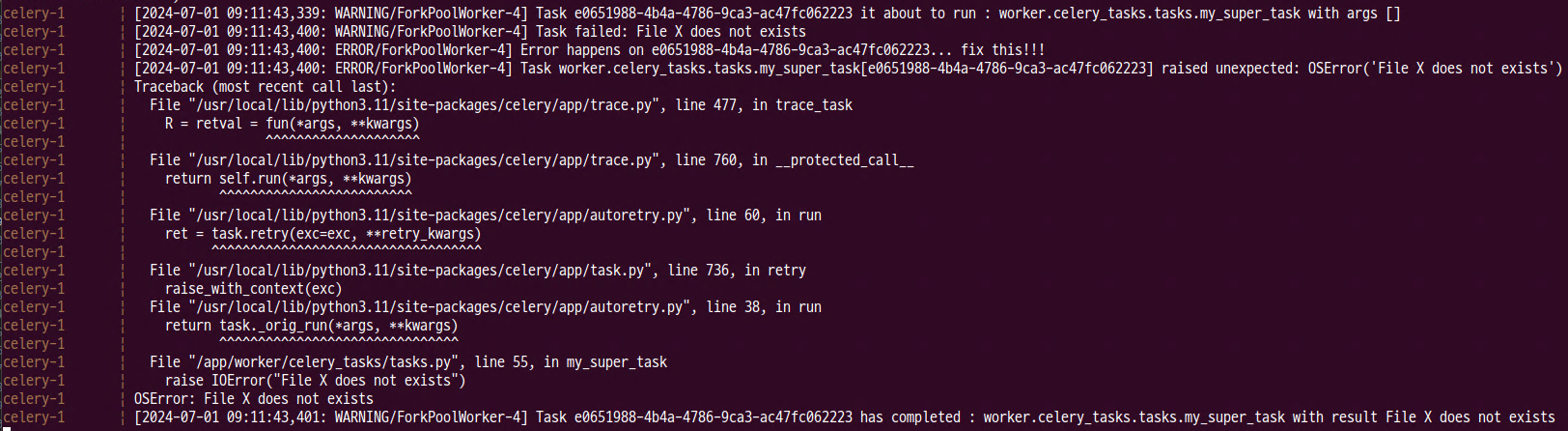
4) Error handling in the group task
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/canvas.html#group-results
- celery 공식 문서에서 제공하는 사용 예시 :
>>> from celery import group
>>> from tasks import add
>>> job = group([
add.s(2, 2),
add.s(4, 4),
add.s(8, 8),
add.s(16, 16),
add.s(32, 32),
])
>>> result = job.apply_async()
>>> result.ready() # have all subtasks completed?
True
>>> result.successful() # were all subtasks successful?
True
>>> result.get()
[4, 8, 16, 32, 64]
- ready, waiting, failed 등이 있으며 revoke는 하나 이상의 subtask가 중간에 멈췄을때 나타나는 현상이다.
- 강의에서 제공하는 사용 예시 :
@app.task(queue="celery")
def is_positive_number(num: int):
if num < 0:
raise ValueError(f"{num} is negative..")
return True
# https://docs.celeryq.dev/en/stable/userguide/canvas.html#group-results
def run_group():
g = group(
is_positive_number.s(2), is_positive_number.s(4), is_positive_number.s(-1)
) # type: ignore
result = g.apply_async()
print(f"ready: {result.ready()}") # have all subtasks completed?
print(f"successful: {result.successful()}") # were all subtasks successful?
try:
result.get()
except ValueError as e:
print(e)
print(f"ready: {result.ready()}") # have all subtasks completed?
print(f"successful: {result.successful()}") # were all subtasks successful?
for elem in result:
print(elem.status)
- app docker 컨테이너에서 shell을 이용한 테스트 :

5) Dead Letter Queue(DLQ) and Dead Letter Exchange(DLX)
- Event Driven System은 크게 3개의 역할로 구분지을 수 있다.
- publisher, event queue, consumer
- 만약 consumer에서 처리에 문제가 생긴 경우, 다른 작업들을 처리하는 consumer가 있기 때문에 특정 작업의 문제로 시스템을 정지하여 처리하기는 쉽지 않다.
- 이런 경우 Dead Letter Queue (DLQ)를 만들어 처리할 수 있다.
- consumer에게 전송되지 않았거나 성공적으로 처리를 하지 못한 경우에 대한 message들을 저장하는 queue이다.
- message들은 아래와 같은 경우가 원인이 될 수 있다.
- consumer가 거절하는 경우
- 시간이 너무 오래 걸려 acknowledgment timeout이 발생한 경우
- 처리를 하는 동안 에러가 발생한 경우
- DQL는 이러한 문제가 되는 messages를 한꺼번에 모아 점검을 하거나, 분석을 한 후에 reprocessing을 하는데 아주 유용하다.
- DLQ와 DLX은 똑같은 의미로 보면 된다.
1. tasks 수정하기
@app.task(bind=True, queue="celery")
def is_positive_number(self, num: int):
try:
if num < 0:
raise ValueError(f"{num} is negative..")
return True
except Exception as e:
traceback_str = traceback.format_exc() # traceback을 문자열로 변경
handle_error.apply_async(args=[self.request.id, str(e), traceback_str])
@app.task(queue="dlq")
def handle_error(task_id, exception, traceback_str):
print(f"task_id: {task_id}")
print(f"exception: {exception}")
print(f"traceback_str: {traceback_str}")
# https://docs.celeryq.dev/en/stable/userguide/canvas.html#group-results
def run_group():
g = group(
is_positive_number.s(2), is_positive_number.s(4), is_positive_number.s(-1)
) # type: ignore
result = g.apply_async()
print(f"ready: {result.ready()}") # have all subtasks completed?
print(f"successful: {result.successful()}") # were all subtasks successful?
try:
result.get()
except ValueError as e:
print(e)
print(f"ready: {result.ready()}") # have all subtasks completed?
print(f"successful: {result.successful()}") # were all subtasks successful?
for elem in result:
print(elem.status)
- traceback :
- traceback은 Python에서 예외 발생 시 호출 스택의 정보를 제공하는 모듈이다. 이 모듈을 사용하면 예외가 발생한 위치와 호출 경로를 확인할 수 있다.
- traceback의 주요 기능은 다음과 같다:
1. 예외 추적 정보 얻기
- traceback.format_exc()를 사용하면 현재 발생한 예외의 추적 정보를 문자열로 얻을 수 있다.
- 이 문자열에는 예외가 발생한 코드의 호출 스택 정보가 포함되어 있다.
2. 호출 스택 정보 얻기
- traceback.extract_stack()을 사용하면 현재 호출 스택의 정보를 얻을 수 있다.
- 이를 통해 함수 호출 경로와 각 함수의 파일 이름, 행 번호 등을 확인할 수 있다.
3. 예외 정보 출력
- traceback.print_exc()를 사용하면 현재 발생한 예외의 추적 정보를 표준 오류 스트림에 출력할 수 있다.
- traceback.print_stack()을 사용하면 현재 호출 스택의 정보를 표준 오류 스트림에 출력할 수 있다.
4. 예외 정보 처리
- traceback.format_exception()을 사용하면 예외 정보를 문자열 리스트로 얻을 수 있다.
- 이를 통해 예외 정보를 로깅, 저장 등의 방식으로 처리할 수 있다.
2. docker-compose에 celery command 수정하기
celery:
build:
context: .
volumes:
- ./app:/app
environment:
POSTGRES_DB: app
POSTGRES_USER: root
POSTGRES_PASSWORD: admin
POSTGRES_HOST: db
command: celery --app=worker worker -l INFO -Q celery,celery1,celery2,dlq
3. app 컨테이너에서 shell로 테스트하기
- except으로 처리를 하고 return 하였기에 celery의 작업은 success로 출력 된다.
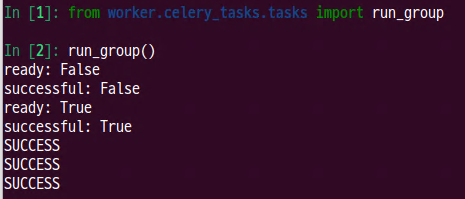
4. celery log 확인하기
- 다른 worker에서 task_id, exception, traceback_str가 출력되는 것을 확인할 수 있다.
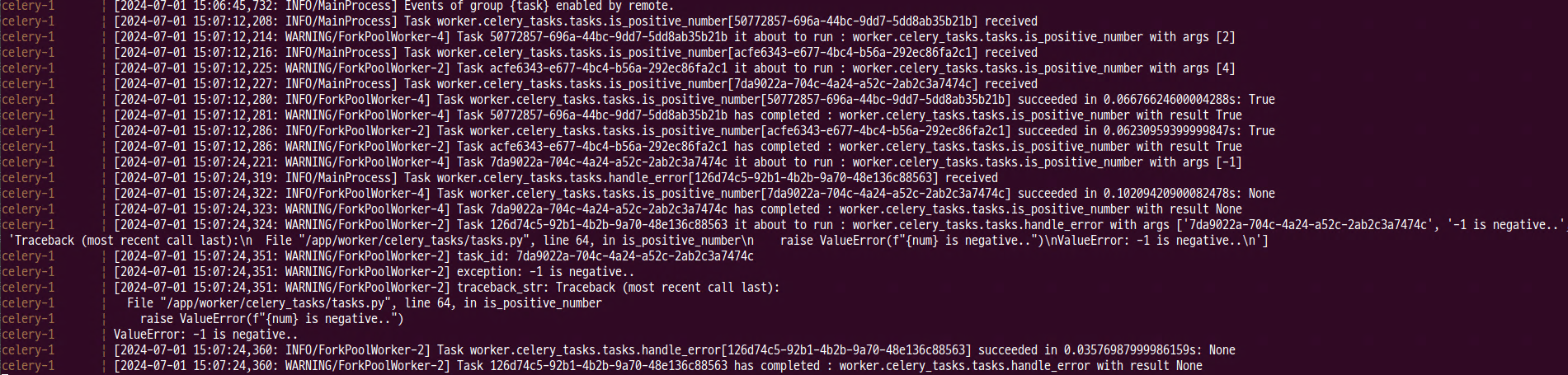
6) Time limit과 Time out에 대한 차이점
- Time Limit
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/workers.html#time-limits
- Task 파라미터 이다.
- seconds level, 즉 초단위로 설정이 가능하다.
- task 자체에서 failure를 만든다.
- Timeout
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/tasks.html
- AsyncResult get을 사용할때 파라미터로 timeout을 사용할 수 있다.
- seconds level, 즉 초단위로 설정이 가능하다.
- timeout 기간이 지나 get에서 에러가 발생할 수 있다. 하지만 실재 task에 에러가 발생한게 아니기 때문에 작업은 성공적으로 종료될 수 있다.
1. Time Limit 코드 추가
# task에 추가
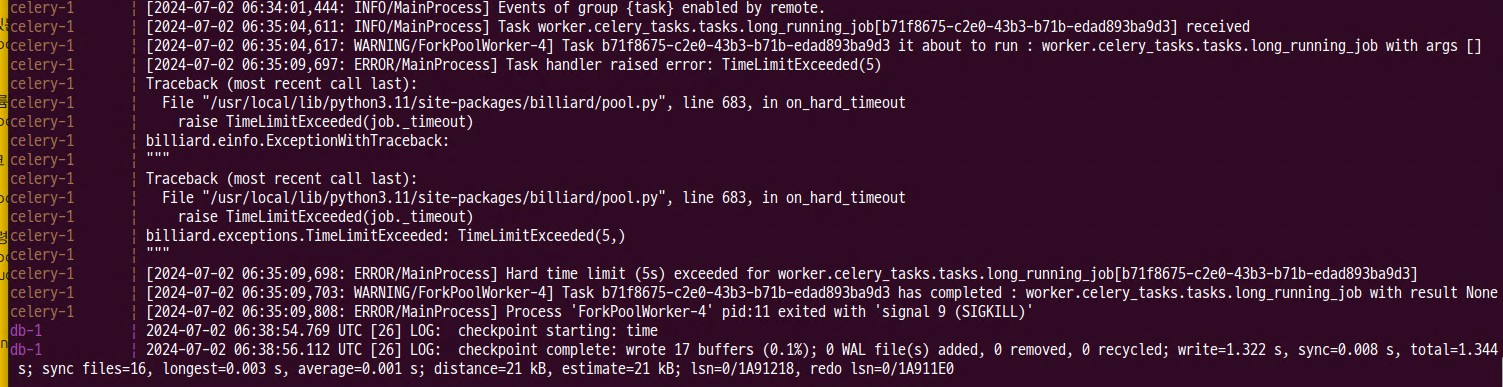
@app.task(queue="celery", time_limit=5)
def long_running_job():
time.sleep(10)
print("finished long_running_job")
- shell에서 테스트 코드 입력
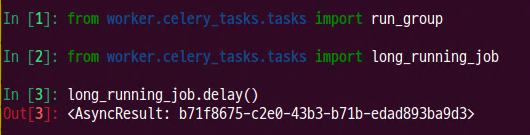
- celery에서 5초 후 종료 확인
2. Timeout 코드 추가
# @app.task(queue="celery", time_limit=5)
@app.task(queue="celery")
def long_running_job():
time.sleep(10)
print("finished long_running_job")
# https://docs.celeryq.dev/en/stable/userguide/canvas.html#group-results
def run_group():
g = group(
is_positive_number.s(2), is_positive_number.s(4), is_positive_number.s(-1)
) # type: ignore
result = g.apply_async()
print(f"ready: {result.ready()}") # have all subtasks completed?
print(f"successful: {result.successful()}") # were all subtasks successful?
try:
result.get()
except ValueError as e:
print(e)
print(f"ready: {result.ready()}") # have all subtasks completed?
print(f"successful: {result.successful()}") # were all subtasks successful?
for elem in result:
print(elem.status)
def simulating_timeout():
result = long_running_job.delay()
result.get(timeout=3)
- shell에서 테스트 코드 입력 및 에러 확인
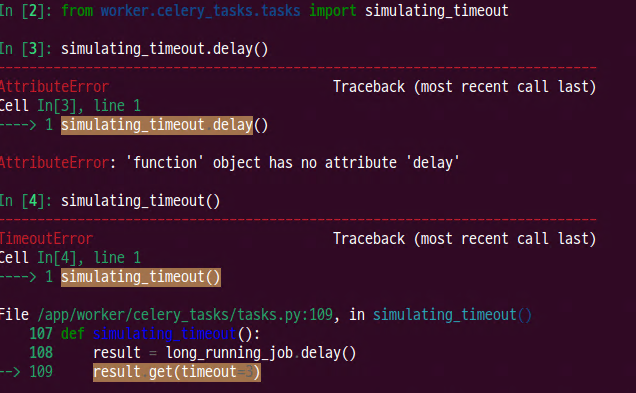
- celery에서 문제 없이 동작 완료 확인

7) Task Callback과 에러 핸들링
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/calling.html#linking-callbacks-errbacks
- chain이랑 비슷하다. 아래 예시 코드에서 2,2의 결과는 4가 된다. 그리고 4와 16의 결과는 20이 된다.
add.apply_async((2, 2), link=add.s(16))
- link_error 실행 옵션을 사용하여 작업에 추가할 수 있다 :
add.apply_async((2, 2), link_error=error_handler.s())
- 또한 link 및 link_error 옵션 모두 목록으로 표현될 수 있다 :
add.apply_async((2, 2), link=[add.s(16), other_task.s()])
- get으로 결과를 받을 때, 그냥 get()만 사용하면 parent, 즉 최초의 실행 결과만 확인할 수 있다. 하위 동작을 get()으로 확인하고 싶다면 children[0].get()을 사용하자.
# parent result
print(result.get())
# child result
print(result.children[0].get())1. link 실습
def simulating_timeout():
result = long_running_job.delay()
result.get(timeout=3)
@app.task(queue="celery")
def multiply(result, z):
return result * z
@app.task(queue="celery")
def error_handler(request, exc, traceback):
print("Task {0} raised exception: {1!r}\n{2!r}".format(request.id, exc, traceback))
def simulating_link():
result = add.apply_async(
args=[2, 3], link=multiply.s(10), link_error=error_handler.s()
) # type: ignore
# parent result
print(result.get())
# child result
print(result.children[0].get())
- shell 테스트 결과
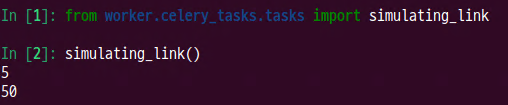
- celery 로그

2. link 에러 실습
@app.task(queue="celery")
def multiply(result, z):
return result * z
@app.task(queue="celery")
def error_handler(request, exc, traceback):
print("Task {0} raised exception: {1!r}\n{2!r}".format(request.id, exc, traceback))
def simulating_link():
result = add.apply_async(
args=[2, "error"], link=multiply.s(10), link_error=error_handler.s()
) # type: ignore
# parent result
print(result.get())
# child result
print(result.children[0].get())
- shell 테스트 결과
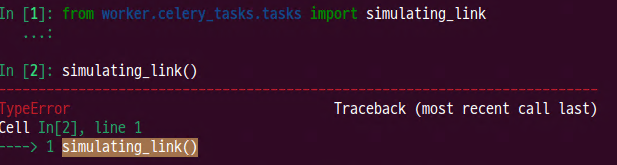
- celery 로그
- Task로 시작하는 에러 로그를 확인할 수 있다.
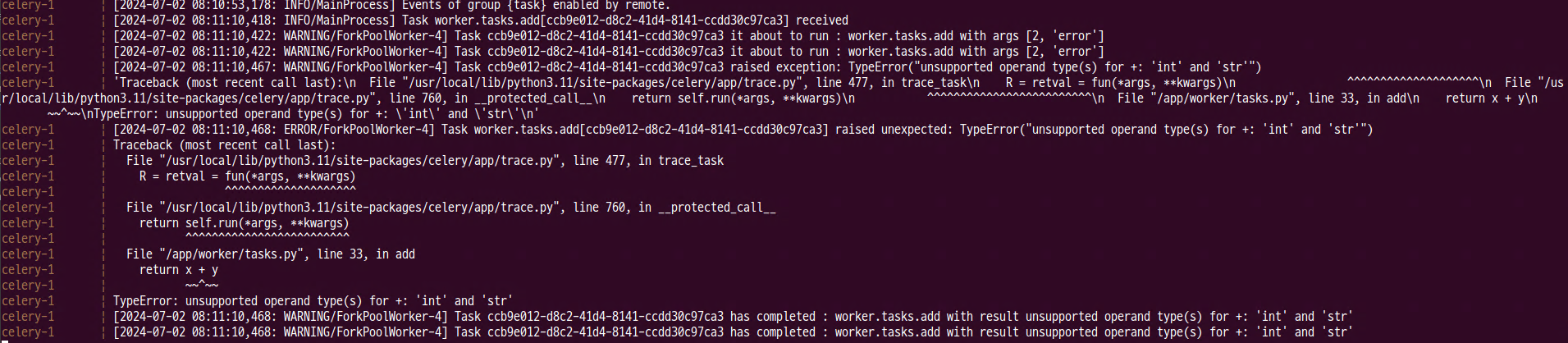
celery-1 | [2024-07-02 08:11:10,468: ERROR/ForkPoolWorker-4] Task worker.tasks.add[ccb9e012-d8c2-41d4-8141-ccdd30c97ca3] raised unexpected: TypeError("unsupported operand type(s) for +: 'int' and 'str'")
8) Task 에러를 Signal로 해결하기
- 관련 페이지 : https://docs.celeryq.dev/en/stable/userguide/signals.html#task-failure
- signal을 이용해 task의 에러를 handle할 수 있다.
1. task_failure 실습 코드
@task_failure.connect(sender=add)
def task_failure_handler(
sender, task_id, exception, args, kwargs, traceback, einfo, **kwargs_extra
):
print(f"Task {task_id} has failed: {sender.name} with exception {exception}")
task_failure_clean_up.delay(task_id=task_id) # type: ignore
@shared_task(queue="celery")
def task_failure_clean_up(task_id, *args, **kwargs):
print(f"Task {task_id} clean up process has been started")
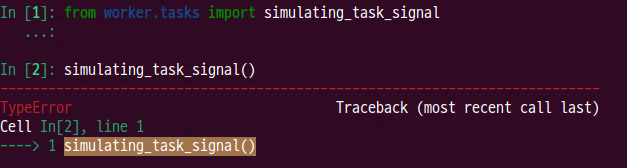
# simulating task signal
def simulating_task_signal():
# Call the Celery task asynchronously
result = add.delay(2, "error") # type: ignore
# Get the result of the task
final_result = result.get()
print("Final Result:", final_result)
- shell을 이용한 테스트 - 에러 발생
- celery 로그
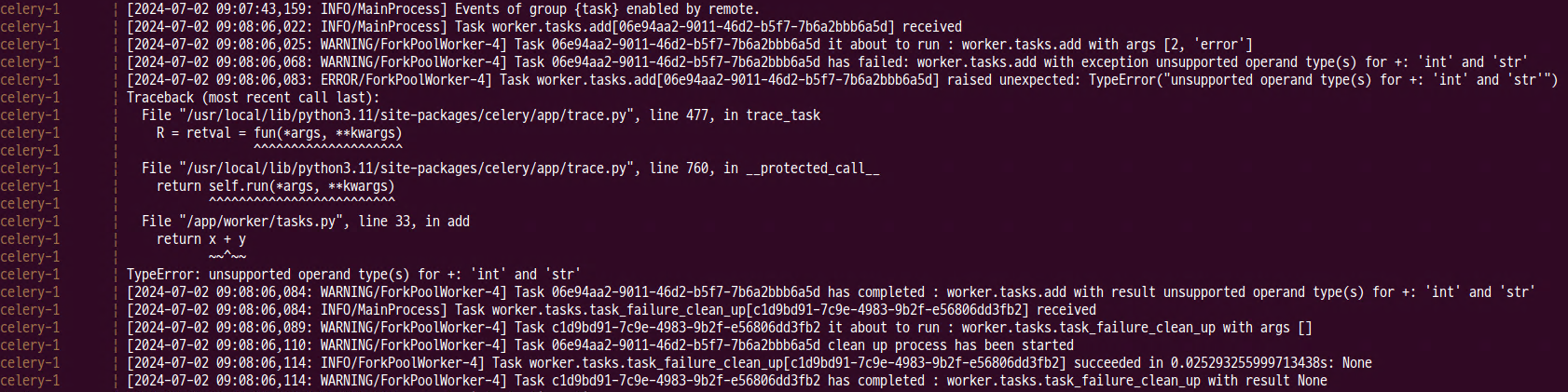
- signal의 동작 순서
- task_prerun -> task_postrun -> task_failure
- reference :
https://velog.io/@qlgks1/Django-Celery-MQ-message-que
Django Celery - async worker celery & redis (message que) basic
API Server <==> Redis(M.Q) <==> Celery stack이해하기. 핵심은 "한정 된 자원"을 잘 활용하기 위해, 여러가지 요청을 "비동기 적으로" 모두 처리하기 위해.
velog.io
Django Celery - 단점, Task & subTask & Signature 비동기 작업 다루기 with network I/O
Celery: Distributed processing worker의 task & subtask(signature) 활용과 실습, 그에 따른 celery의 단점과 해결법.
velog.io
Django Celery - Task 그룹 작업, 선후행 Chain, 일괄 처리 (배치) Group & Chord
task 자체와 실행에 초점을 살펴본 앞 글에 이어, task의 선&후행 실행(chaining)과 grouping하여 chord와 같이 task를 묶고 `for-loop` 없이 한 꺼번에 비동기 작업을 수행하는 것에 대해 알아보자.
velog.io
https://velog.io/@qlgks1/Django-Celery-Safety-Efficiency
Django Celery - (마지막) 셀러리 안정적 완료, 효율적 처리, 커스터마이제이션
[PyCon korea 발표 "셀러리 핵심과 커스터마이제이션" 정리] celery를 다루면서 1.안정적 완료, 2.효율적 처리, 3.고도화 및 커스터마이제이션에 대한 얘기를 정리하며 부족한 정보는 채우고 핵심에 대
velog.io
Django Celery - 효과적인 디버깅 & 모니터링: Logging + Flower + Prometheus + Grafana(with Loki & Promtail)
celery는 퍼포먼스 체크나 디버깅이 쉽지않다. celery를 전체적으로 최적화 및 depth있는 분석을 위해 기본적인 모니터링 환경을 구성하고, 더 나아가 전체 web stack [Prometheus + Grafana + Loki + Promtail] 구
velog.io