[인프런] 실전! Redis 활용 학습 정리
https://www.inflearn.com/course/%EC%8B%A4%EC%A0%84-redis-%ED%99%9C%EC%9A%A9/dashboard
실전! Redis 활용 강의 | 신동현 - 인프런
신동현 | 배워서 바로 사용할 수 있는 Redis 강좌입니다!, 튜토리얼 수준의 강의는 그만 🙅♂️다양한 예제를 통해 실무에 바로 적용할 수 있는 Redis 강의입니다! [임베딩 영상] Key-Value NoSQL 부동
www.inflearn.com
http://redisgate.kr/redis/introduction/redis_intro.php
Redis Introduction
redis_intro Redis Introduction Redis Introduction 주요 특징 데이터 저장소로 디스크가 아닌 메모리를 사용합니다. 그리고 데이터의 안전한 보관과 백업을 위해 다른 서버의 메모리에 실시간으로 복사본
redisgate.kr
1. 데이터 타입(Data Type)
1) String
- 문자열, 숫자, serialized object(JSON string) 등 저장
- 실습 코드
$ SET lecture inflearn-redis
$ MSET price 100 language ko
$ MGET lecture price language
$ INCR price
$ INCRBY price 10
$ SET inflearn-redis ‘{“lecture”: “inflearn-redis”, “language”: “en”}’
$ SET inflearn-redis:ko:price 200
- 실습 결과

2) Lists
- String을 Linked List로 저장 -> push / pop에 최적화 O(1) Queue(FIFO) / Stack(FILO) 구현에 사용
- 왼쪽으로 데이터를 가져오면 stack 오른쪽으로 데이터를 가져오면 queue가 된다.


| 구분 | 스택(Stack) | 큐(Queue) |
| 자료구조 | LIFO (Last In, First Out) | FIFO (First In, First Out) |
| 연산 | push(삽입), pop(삭제) | enqueue(삽입), dequeue(삭제) |
| 활용 사례 | 함수 호출, 괄호 짝 맞추기, 호위 표기법 계산 등 | 프린터 대기열, 버퍼 관리, 스케줄링 알고리즘 |
| 구현 방법 | 배열, 연결리스트 | 배열, 연결리스트 |
- 실습 코드
$ LPUSH queue job1 job2 job3
$ RPOP queue
$ LPUSH stack job1 job2 job3
$ LPOP stack
$ LPUSH queue job1 job2 job3
$ LRANGE queue -2 -1
$ LTRIM queue 0 0
- 실습 결과
127.0.0.1:6379> LPUSH queue job1 job2 job3
(integer) 3
127.0.0.1:6379> RPOP queue
"job1"
127.0.0.1:6379> LPUSH stack job1 job2 job3
(integer) 3
127.0.0.1:6379> LPOP stack
"job3"
127.0.0.1:6379> LPUSH queue job4 job5
(integer) 4
127.0.0.1:6379> LRANGE queue 0 -1
1) "job5"
2) "job4"
3) "job3"
4) "job2"
127.0.0.1:6379> LRANGE queue -2 -1
1) "job3"
2) "job2"
127.0.0.1:6379> LRANGE queue 2 3
1) "job3"
2) "job2"
127.0.0.1:6379> LTRIM queue 0 1
OK
127.0.0.1:6379> LRANGE queue 0 -1
1) "job5"
2) "job4"
127.0.0.1:6379>
3) Sets
- Unique string을 저장하는 정렬되지 않은 집합, 입력하는 데이터의 순서를 보장하지 않는다.
- Set Operation 사용 가능(e.g. intersection, union, difference)

- 명령어 정리
- sadd : set에 데이터 추가, 중복된 데이터가 있으면 제거되며 한번만 추가가 된다.
- smembers : set의 모든 멤버 출력
- scard : set의 카디널리티(Cardinality), 특정 데이터 집합의 유니크(Unique)한 값의 개수를 출력한다.
- sismember : 특정 아이템이 set에 포함되어 있는지 확인할 수 있다.
- sinter : 최대 10개 이하의 set에 포함된 공통된 데이터, 교집합을 출력한다.
- sinterstore : Redis에서 여러 개의 set들의 교집합을 계산하고, 그 결과를 새로운 set으로 저장하는 명령어이다.
- sdiff : N개의 set을 입력으로 받아 첫번째 set에서 나머지 set들을 뺀 차집합의 결과를 얻을 수 있다.
- sunion : N개의 set을 입력으로 받아 합집합을 출력한다.
- 실습 코드
$ SADD user:1:fruits apple banana orange orange
$ SMEMBERS user:1:fruits
$ SCARD user:1:fruits
$ SISMEMBER user:1:fruits banana
$ SADD user:2:fruits apple lemon
$ SINTER user:1:fruits user:2:fruits
$ SDIFF user:1:fruits user:2:fruits
$ SUNION user:1:fruits user:2:fruits
- 실습 결과
127.0.0.1:6379> SADD user:1:fruits apple banana orange orange
(integer) 3
127.0.0.1:6379> SMEMBERS user:1:fruits
1) "banana"
2) "orange"
3) "apple"
127.0.0.1:6379> SCARD user:1:fruits
(integer) 3
127.0.0.1:6379> SISMEMBER user:1:fruits banana
(integer) 1
127.0.0.1:6379> SADD user:2:fruits apple lemon
(integer) 2
127.0.0.1:6379> SINTER user:1:fruits user:2:fruits
1) "apple"
127.0.0.1:6379> SDIFF user:1:fruits user:2:fruits
1) "banana"
2) "orange"
127.0.0.1:6379> SDIFF user:2:fruits user:1:fruits
1) "lemon"
127.0.0.1:6379> SUNION user:1:fruits user:2:fruits
1) "banana"
2) "lemon"
3) "apple"
4) "orange"
4) Hashes
- field-value 구조를 갖는 데이터 타입으로 dict나 map과 유사한 개념이다.
- 다양한 속성을 갖는 객체의 데이터를 저장할 때 유용하다.
- 실습 코드
$ HSET lecture name inflearn-redis price 100 language ko
$ HGET lecture name
$ HMGET lecture price language invalid
$ HINCRBY lecture price 10
- 실습 결과
- 유효하지 않은 필드 값을 추가해서 요청할 때, 없는 필드 값은 nil로 반환된다.
127.0.0.1:6379> HSET lecture name inflearn-redis price 100 language ko
(integer) 3
127.0.0.1:6379> HGET lecture price
"100"
127.0.0.1:6379> HGET lecture language
"ko"
127.0.0.1:6379> HMGET lecture name price language invalid
1) "inflearn-redis"
2) "100"
3) "ko"
4) (nil)
127.0.0.1:6379> HINCRBY lecture price 10
(integer) 110
127.0.0.1:6379> HINCRBY lecture name 1
(error) ERR hash value is not an integer
127.0.0.1:6379>
5) Sorted Sets
- Sorted Sets은 줄여서 zset이라 불린다.
- Set과 유사하지만 score라는 추가 필드를 가지고 있음으로서 해당 score를 이용해 데이터를 미리 정렬하는 데이터 타입이다.
- Unique string을 연관된 score를 통해 정렬된 집합(Set의 기능 + 추가로 score 속성 저장)
- 내부적으로 Skip List + Hash Table로 이루어져 있고, 값을 추가하는 순간에 score 값에 따라 정렬 유지
- score가 동일하면 lexicographically(사전 편찬 순) 정렬
- 입력 방법으로 score를 먼저 정의하고 해당하는 멤버의 값을 뒤에 써주게 된다.
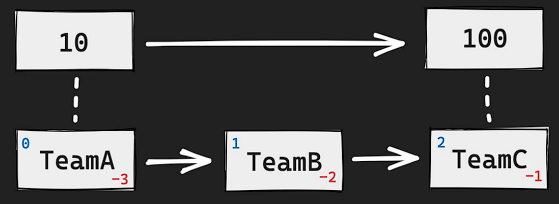
- 실습 코드
$ ZADD points 10 TeamA 10 TeamB 50 TeamC
$ ZRANGE points 0 -1
$ ZRANGE points 0 -1 REV WITHSCORES
$ ZRANK points TeamA
- TeamA와 TeamB는 같은 점수를 가지고 있기 때문에 사전편찬순으로 TeamA가 우선순위를 가진다.
- 순서가 있는 데이터 타입이기에 range 명령어로 index를 통해 특정 범위를 조회할 수 있다.
- REV : 역순으로 반환
- WITHSCORES : 스코어와 함께 반환
- ZRANK를 이용하면 해당 아이템의 RANK를 반환한다. 이 RANK는 0부터 시작한 index 값과 동일하다.
- 실습 결과
- rev 옵션은 redis 6.2버전 이상에서 지원이 된다.
127.0.0.1:6379> ZADD points 10 TeamA 10 TeamB 50 TeamC
(integer) 3
127.0.0.1:6379> ZRANGE points 0 -1
1) "TeamA"
2) "TeamB"
3) "TeamC"
127.0.0.1:6379> ZRANGE points 0 -1 REV WITHSCORES
(error) ERR syntax error
127.0.0.1:6379> ZREVRANGE points 0 -1 WITHSCORES
1) "TeamC"
2) "50"
3) "TeamB"
4) "10"
5) "TeamA"
6) "10"
127.0.0.1:6379> ZRANK points TeamA
(integer) 0
127.0.0.1:6379> ZRANK points TeamB
(integer) 1
127.0.0.1:6379> ZRANK points TeamC
(integer) 2
127.0.0.1:6379>
6) Streams
- append-only log에 consumer groups과 같은 기능을 더한 자료 구조, kafka와 같은 이벤트 스트림 플랫폼과 유사한 부분이 있다.
- append-only log란 databse나 분산시스템에 사용되는 데이터 저장 알고리즘으로 데이터가 수정되거나 삭제되지 않고 항상 추가만 되는 구조를 가지고 있다.
- stream에 추가되는 이벤트 또는 메시지는 고유 id를 가진다. 고유 id는 스트림에 추가되는 시간과 생성 기준으로 redis에 자동 할당되는데 이런 고유 id를 통해 해당 엔트리를 읽을때 상수의 시간 복잡도를 가지게 된다.
- 상수 시간 복잡도(Constant Time Complexity) :
- 알고리즘의 시간 복잡도 중 가장 효율적인 유형이다. 이는 알고리즘의 실행 시간이 입력 크기와 무관하게 일정한 시간이 소요되는 것을 의미한다.
- 즉, 입력 데이터의 크기가 어떻게 변경되더라도 알고리즘의 실행 시간은 항상 일정하게 유지된다. 이러한 알고리즘은 O(1)이라고 표기된다.
- 예를 들어, 배열에서 특정 인덱스의 값을 가져오는 작업은 상수 시간 복잡도를 가진다. 배열의 크기가 아무리 크더라도 특정 인덱스의 값을 가져오는 데 걸리는 시간은 일정하다.
- 또 다른 예로, 변수에 값을 할당하는 작업도 상수 시간 복잡도를 가진다. 변수에 값을 할당하는 데 걸리는 시간은 입력 크기와 무관하게 일정하다.
- 상수 시간 복잡도는 알고리즘 설계 시 가장 이상적인 목표이다. 이는 입력 크기에 상관없이 일정한 시간 내에 작업을 수행할 수 있기 때문에 매우 효율적이다. 하지만 모든 알고리즘이 상수 시간 복잡도를 가질 수는 없으며, 이러한 알고리즘은 일반적으로 매우 단순한 작업에만 적용된다.
- 추가 기능 :
- Unique id를 통해 하나의 entry를 읽을 때, O(1) 시간 복잡도 가지게 됨
- Consumer Group을 통해 분산 시스템에서 다수의 consumer가 event 처리가 가능함
- 동일한 메시지를 여러번 처리해야 하는 경우가 있는데 이때 consumer group을 이용하면 다수의 consumer가 메시지를 처리하면서도 동일한 메시지를 중복 처리하는 문제를 쉽게 해결할 수 있다.
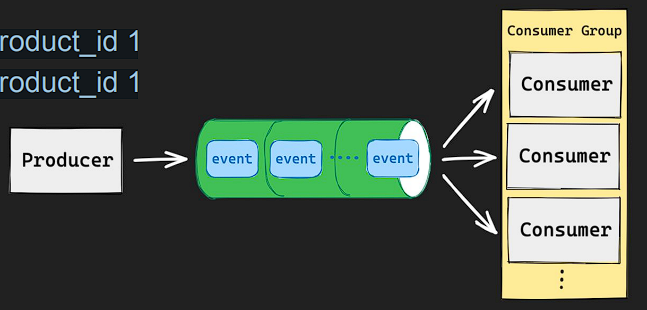
- 명령어 정리 :
1. xadd: 새로운 메시지를 스트림에 추가합니다.
- 구문: XADD stream_name [MAXLEN [~] count] * [field value ...]
- 새로운 메시지를 스트림에 추가하고, 선택적으로 스트림의 최대 길이를 제한할 수 있습니다.
- * 옵션을 주면 unique id를 자동을 할당한다.
2. xrange: 스트림의 특정 범위에 있는 메시지를 가져옵니다.
- 구문: XRANGE stream_name start end [COUNT count]
- 스트림에서 지정된 범위의 메시지를 가져오며, 선택적으로 가져올 메시지의 수를 제한할 수 있습니다.
- start와 end는 메시지 ID를 나타내며, 메시지 ID는 타임스탬프와 순차 번호로 구성됩니다.
- COUNT 옵션을 사용하면 반환되는 메시지 수를 제한할 수 있습니다.
합니다.
- 예시:
- XRANGE mystream 1516293313000-0 1516293343000-0 COUNT 10
- 위 명령은 mystream 스트림에서 1516293313000-0부터 1516293343000-0 사이의 메시지 중 최대 10개를 반환
3. xrevrange: 스트림의 특정 범위에 있는 메시지를 역순으로 가져옵니다.
- 구문: XREVRANGE stream_name end start [COUNT count]
- 스트림에서 지정된 범위의 메시지를 역순으로 가져오며, 선택적으로 가져올 메시지의 수를 제한할 수 있습니다.
4. xlen: 스트림의 길이를 반환합니다.
- 구문: XLEN stream_name
- 스트림에 저장된 메시지의 총 개수를 반환합니다.
5. xdel: 스트림에서 지정된 메시지를 삭제합니다.
- 구문: XDEL stream_name id [id ...]
- 스트림에서 하나 이상의 메시지를 삭제합니다.
6 . xtrim: 스트림의 크기를 제한합니다.
- 구문: XTRIM stream_name MAXLEN [~] count
- 스트림의 크기를 지정된 값 이하로 유지하도록 오래된 메시지를 삭제합니다.
7. xread: 스트림에서 새로운 메시지를 읽어옵니다.
- 구문: XREAD [COUNT count] [BLOCK milliseconds] STREAMS stream_name [stream_name ...] id [id ...]
- 스트림에서 새로운 메시지를 읽어오며, 선택적으로 메시지 수와 대기 시간을 제한할 수 있습니다.
8. xgroup: 소비자 그룹을 관리합니다.
- 구문: XGROUP CREATE stream_name group_name id
- 새로운 소비자 그룹을 생성하거나 기존 그룹을 관리합니다.
- 실습 코드
$ XADD events * action like user_id 1 product_id 1
$ XADD events * action like user_id 2 product_id 1
$ XRANGE events - +
$ XDEL events [id]
- xrange events - + : 가장 처음으로 들어갔던 이벤트 부터 나중에 들어간 이벤트까지 모두 출력해준다.
- 실습 결과
127.0.0.1:6379> XADD events * action like user_id 1 product_id 1
"1720077729705-0"
127.0.0.1:6379> XADD events * action like user_id 2 product_id 1
"1720077732560-0"
127.0.0.1:6379> XRANGE events - +
1) 1) "1720077729705-0"
2) 1) "action"
2) "like"
3) "user_id"
4) "1"
5) "product_id"
6) "1"
2) 1) "1720077732560-0"
2) 1) "action"
2) "like"
3) "user_id"
4) "2"
5) "product_id"
6) "1"
127.0.0.1:6379> xdel events 1720077729705-0
(integer) 1
127.0.0.1:6379> XRANGE events - +
1) 1) "1720077732560-0"
2) 1) "action"
2) "like"
3) "user_id"
4) "2"
5) "product_id"
6) "1"
127.0.0.1:6379>
7) Geospatials
- Geospatial Indexes : 좌표를 저장하고, 검색하는 데이터 타입 거리 계산, 범위 탐색 등 지원
- 정보를 입력할 때, 경도/위도 순서로 입력을 해야 한다.
- 명령어 :
- GEOADD: 지리 공간 데이터를 Redis 데이터베이스에 추가합니다. 위도, 경도, 멤버를 인수로 받습니다.
- 예) GEOADD places 37.7749 -122.4194 "San Francisco"
- GEOPOS: 주어진 멤버의 위치(위도, 경도)를 반환합니다.
- 예) GEOPOS places "San Francisco"
- GEODIST: 두 멤버 사이의 거리를 계산합니다.
- 예) GEODIST places "San Francisco" "Los Angeles" km
- GEORADIUS: 주어진 중심점과 반경 내에 있는 멤버를 반환합니다.
- 예) GEORADIUS places 37.7749 -122.4194 100 km WITHDIST
- GEORADIUSBYMEMBER: 주어진 멤버를 중심으로 반경 내에 있는 멤버를 반환합니다.
- 예) GEORADIUSBYMEMBER places "San Francisco" 100 km WITHDIST
- GEOHASH: 주어진 멤버의 Geohash 값을 반환합니다.
- 예) GEOHASH places "San Francisco"
- 실습 코드
$ GEOADD seoul:station 126.923917 37.556944 hong-dae 127.027583 37.497928 gang-nam
$ GEODIST seoul:station hong-dae gang-nam KM
- 실습 결과
127.0.0.1:6379> GEOADD seoul:station 126.923917 37.556944 hong-dae 127.027583 37.497928 gang-nam
(integer) 2
127.0.0.1:6379> GEODIST seoul:station hong-dae gang-nam km
"11.2561"
127.0.0.1:6379>
8) Bitmaps
- 실제 데이터 타입은 아니고, String에 binary operation을 적용한 것
- 적은 메모리를 사용해 바이너리의 상태값을 저장하는데 많이 사용함
- 최대 42억개 binary 데이터 표현 = 2^32(4,294,967,296)
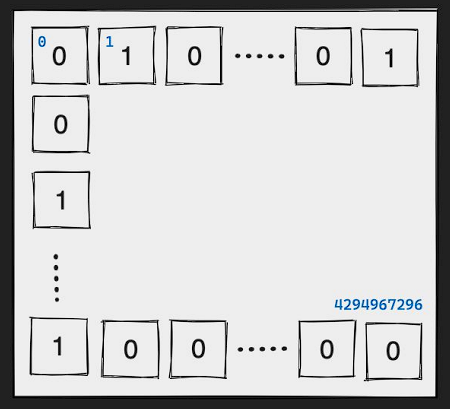
- 명령어 :
- setbit
- 설명: 지정된 위치에 비트 값을 설정합니다.
- 옵션: setbit key offset value
- 사용 예시:
# 키 'mykey'의 0번째 비트를 1로 설정
redis> setbit mykey 0 1
(integer) 0
- getbit
- 설명: 지정된 위치의 비트 값을 가져옵니다.
- 옵션: getbit key offset
- 사용 예시:
# 키 'mykey'의 0번째 비트 값 확인
redis> getbit mykey 0
(integer) 1
- bitcount
- 설명: 지정된 범위의 비트 값이 1인 비트 수를 세어 반환합니다.
- 옵션: bitcount key [start end]
- 사용 예시:
# 키 'mykey'의 모든 비트 중 1인 비트 수 확인
redis> bitcount mykey
(integer) 1
# 키 'mykey'의 0번째부터 5번째 비트 중 1인 비트 수 확인
redis> bitcount mykey 0 5
(integer) 1
- bitop
- 설명: 여러 키의 비트 연산 결과를 저장합니다.
- 옵션: bitop operation destkey key [key ...]
- 사용 예시:
# 키 'key1'과 'key2'의 AND 연산 결과를 'destination'에 저장
redis> bitop and destination key1 key2
(integer) 1
# 키 'key1', 'key2', 'key3'의 OR 연산 결과를 'destination'에 저장
redis> bitop or destination key1 key2 key3
(integer) 1
- bitpos
- 설명: 지정된 범위에서 첫 번째로 나타나는 0 또는 1 비트의 위치를 반환합니다.
- 옵션: bitpos key bit [start] [end]
- 사용 예시:
# 키 'mykey'에서 첫 번째로 나타나는 0 비트의 위치 확인
redis> bitpos mykey 0
(integer) 1
# 키 'mykey'에서 1번째부터 5번째 비트 사이에서 첫 번째로 나타나는 1 비트의 위치 확인
redis> bitpos mykey 1 1 5
(integer) 3
- bitfield
- 설명: 비트 필드 내의 특정 비트 범위를 읽거나 쓰는 명령입니다.
- 옵션: bitfield key [get type offset] [set type offset value] [incrby type offset increment] ...
- 사용 예시:
# 키 'mykey'의 0번째 비트부터 5번째 비트까지의 값을 읽기
redis> bitfield mykey get u6 0
1) (integer) 42
# 키 'mykey'의 0번째 비트부터 5번째 비트까지의 값을 63으로 설정하기
redis> bitfield mykey set u6 0 63
1) (integer) 42
# 키 'mykey'의 0번째 비트부터 5번째 비트까지의 값을 1 증가시키기
redis> bitfield mykey incrby u6 0 1
1) (integer) 43
- 실습 코드
$ SETBIT user:log-in:23-01-01 123 1 # 유저 로그인
$ SETBIT user:log-in:23-01-01 456 1 # 유저 로그인
$ SETBIT user:log-in:23-01-02 123 1 # 유저 로그인
$ BITCOUNT user:log-in:23-01-01 # 1일에 로그인 한 유저 출력
$ BITOP AND result user:log-in:23-01-01 user:log-in:23-01-02 # 1일과 2일에 로그인 한 유저 출력
$ GETBIT result 123 # 결과는 바로 출력되지 않고 result 키에 저장됨
- 실습 결과
127.0.0.1:6379> SETBIT user:log-in:23-01-01 123 1
(integer) 0
127.0.0.1:6379> SETBIT user:log-in:23-01-01 456 1
(integer) 0
127.0.0.1:6379> SETBIT user:log-in:23-01-02 123 1
(integer) 0
127.0.0.1:6379> BITCOUNT user:log-in:23-01-01
(integer) 2
127.0.0.1:6379> BITCOUNT user:log-in:23-01-02
(integer) 1
127.0.0.1:6379> BITOP AND result user:log-in:23-01-01 user:log-in:23-01-02
(integer) 58
127.0.0.1:6379> GETBIT result 123
(integer) 1
127.0.0.1:6379>
9) HyperLogLog
- 집합의 cardinality를 추정할 수 있는 확률형 자료구조
- 정확성을 일부 포기하는 대신 저장공간을 효율적으로 사용(평균 에러 0.81%)

- Redis의 HyperLogLog(HLL)은 집합의 유일한 요소 개수를 효율적으로 추정하는 데 사용되는 확률적 데이터 구조입니다. HLL은 메모리 사용량이 매우 작고 정확도가 높은 특징이 있습니다.
- HLL의 주요 명령어와 설명은 다음과 같습니다:
1. PFADD key element [element ...]
- 지정된 키에 하나 이상의 요소를 추가합니다.
- 예시: PFADD hll_key "apple" "banana" "cherry"
2. PFCOUNT key [key ...]
- 지정된 키에 저장된 유일한 요소의 개수를 추정합니다.
- 예시: PFCOUNT hll_key
3. PFMERGE destkey sourcekey [sourcekey ...]
- 여러 개의 HLL을 병합하여 하나의 HLL로 만듭니다.
- 예시: PFMERGE merged_hll hll_key1 hll_key2 hll_key3
- 옵션:
- WITHCOUNT: PFCOUNT 명령어를 실행할 때, 추정된 유일한 요소 개수를 출력합니다.
- 예시: PFCOUNT hll_key WITHCOUNT
- RESET: PFADD 명령어를 사용할 때, 기존 HLL을 초기화하고 새로운 요소를 추가합니다.
- 예시: PFADD hll_key "apple" "banana" "cherry" RESET
- 특징:
- HLL은 메모리 사용량이 매우 작아 대규모 데이터 처리에 유용합니다.
- 정확도는 약 99.9%로 매우 높습니다.
- 유일한 요소 개수 추정에 특화되어 있어, 중복 요소를 제거하는 데 효과적입니다.
- 사용 예시:
1. 웹 사이트 방문자 수 추정
- 각 방문자의 IP 주소를 HLL에 추가하여 유일한 방문자 수를 추정할 수 있습니다.
- PFADD visitors_hll "192.168.1.100" "192.168.1.101" "192.168.1.102"
- PFCOUNT visitors_hll
2. 소셜 미디어 사용자 수 추정
- 각 사용자의 ID를 HLL에 추가하여 유일한 사용자 수를 추정할 수 있습니다.
- PFADD social_users_hll "user1" "user2" "user3"
- PFCOUNT social_users_hll
3. 여러 HLL 병합
- 각 지역별 HLL을 병합하여 전체 유일한 사용자 수를 추정할 수 있습니다.
- PFMERGE global_hll region1_hll region2_hll region3_hll
- PFCOUNT global_hll
- 사용 시 주의사항:
- HyperLogLog는 근사값 카운팅 알고리즘을 사용하므로 정확도가 100%는 아닙니다. 일반적으로 0.81% 오차 범위 내에서 작동합니다.
- HyperLogLog는 메모리 사용량이 작지만, 데이터 크기가 커질수록 오차 범위가 커질 수 있습니다.
- HyperLogLog는 중복 데이터를 효과적으로 처리할 수 있지만, 개별 데이터를 추적할 수는 없습니다.
- HyperLogLog는 정확한 카운트가 필요한 경우보다는 근사값 카운팅이 필요한 경우에 더 적합합니다.
-
- 실습 코드
127.0.0.1:6379> PFADD fruits apple orange grape kiwi
(integer) 1
127.0.0.1:6379> PFCOUNT fruits
(integer) 4
127.0.0.1:6379> PFADD fruits apple
(integer) 0
127.0.0.1:6379> PFCOUNT fruits
(integer) 4
- 실습 결과
>> for ((i=1; i<=1000; i++)); do redis-cli SADD k1 $i; done
127.0.0.1:6379> memory usage k1
(integer) 40296
127.0.0.1:6379> scard k1
(integer) 1000
127.0.0.1:6379>
>> for ((i=1; i<1000; i++)); do redis-cli PFADD k2 $i; done
127.0.0.1:6379> memory usage k2
(integer) 2608
127.0.0.1:6379> pfcount k2
(integer) 1000
10) BloomFilter
- element가 집합 안에 포함되었는지 확인할 수 있는 확률형 자료 구조
- (=membership test) : 정확성을 일부 포기하는 대신 저장공간을 효율적으로 사용
- false positive : element가 집합에 실제로 포함되지 않은데 포함되었다고 잘못 예측하는 경우
- vs. Set : 실제 값을 저장하지 않기 때문에 매우 적은 메모리 사용

- Redis의 BloomFilter는 공간 효율적인 확률적 데이터 구조로, 집합 멤버십 테스트를 위해 사용된다.
- 이는 데이터의 존재 여부를 빠르게 확인할 수 있지만, 일부 false positive 결과가 발생할 수 있다.
- Bloom Filter는 false positive는 허용하지만 false negative는 허용하지 않는다.
- false positive와 false negative에 대한 자세한 설명:
- false positive:
- 요소가 실제로는 BloomFilter에 저장되어 있지 않지만, BFEXISTS 명령어가 요소가 존재한다고 잘못 알려주는 경우이다.
- 이는 해시 함수의 충돌로 인해 발생할 수 있다. false positive 확률은 BloomFilter의 크기와 저장된 요소 수에 따라 달라진다.
- false negative:
- 요소가 실제로는 BloomFilter에 저장되어 있지만, BFEXISTS 명령어가 요소가 존재하지 않는다고 잘못 알려주는 경우이다.
- 이는 BloomFilter에서 절대 발생하지 않는다. BloomFilter는 요소의 존재 여부를 정확하게 판단할 수 있다.
- 명령어 :
1. BF.ADD key element
- 설명: 지정된 키에 요소를 추가합니다.
- 반환값: 0 (요소가 이미 존재하는 경우) 또는 1 (요소가 새로 추가된 경우)
- 예시: BF.ADD myfilter "hello"
2. BF.EXISTS key element
- 설명: 지정된 키에 요소가 존재하는지 확인합니다.
- 반환값: 0 (요소가 존재하지 않음) 또는 1 (요소가 존재함)
- 예시: BF.EXISTS myfilter "hello"
3. BF.MADD key element [element ...]
- 설명: 지정된 키에 여러 요소를 한 번에 추가합니다.
- 반환값: 추가된 요소 수
- 예시: BF.MADD myfilter "hello" "world" "foo" "bar"
4. BF.MEXISTS key element [element ...]
- 설명: 지정된 키에 여러 요소가 존재하는지 확인합니다.
- 반환값: 존재하는 요소 수
- 예시: BF.MEXISTS myfilter "hello" "world" "foo" "bar"
5. BF.INSERT key [CAPACITY capacity] [EXPANSION expansion]
[ERROR error] [NOCREATE] element [element ...]
- 설명: 지정된 키에 새로운 BloomFilter를 생성하고 요소를 추가합니다.
- 옵션:
- CAPACITY capacity: BloomFilter의 초기 용량 (기본값: 100)
- EXPANSION expansion: BloomFilter의 확장 비율 (기본값: 2)
- ERROR error: 허용되는 최대 오류 확률 (기본값: 0.01)
- NOCREATE: 기존 BloomFilter만 사용하고 새로 생성하지 않음
- 반환값: 추가된 요소 수
- 예시: BF.INSERT myfilter CAPACITY 1000 ERROR 0.001 "hello" "world" "foo" "bar"
- 옵션 예시:
- CAPACITY 1000: BloomFilter의 초기 용량을 1000으로 설정
- ERROR 0.001: 허용되는 최대 오류 확률을 0.1%로 설정
6. BF.INFO key
- 설명: 지정된 키의 BloomFilter 정보를 반환합니다.
- 옵션: 없음
- 반환값: BloomFilter의 용량, 오류 확률, 요소 수 등의 정보
- 예시: BF.INFO myfilter
- 실습 코드
$ BF.MADD fruits apple orange
$ BF.EXISTS fruits apple
$ BF.EXISTS fruits grape
- 실습 결과
- BloomFilter를 사용하려면 설치해야 하는 패키지들이 몇가지 있다. 때문에 docker를 사용해 쉽게 환경을 구성한다.
docker run -p 63790:6379 -d --rm redis/redis-stack-serverredis-cli -p 63790
127.0.0.1:63790> BF.MADD fruits apple orange grape
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:63790> BF.EXISTS fruits apple
(integer) 1
127.0.0.1:63790> BF.EXISTS fruits banana
(integer) 0
127.0.0.1:63790>
* BloomFilter와 HyperLogLog의 비교 정리
1. BloomFilter
- 목적: 집합 멤버십 테스트(Set Membership Test)
- 특성:
- 데이터 구조: 비트 배열
- 확률적 데이터 구조로, 거짓 양성(false positive) 오류가 발생할 수 있음
- 거짓 음성(false negative) 오류는 발생하지 않음
- 데이터 추가는 가능하지만, 데이터 삭제는 불가능
- 사용 사례:
- 스팸 필터링
- 중복 URL 감지
- 캐시 효율성 향상
2. HyperLogLog
- 목적: 중복 제거 후 집합의 크기 추정
- 특성:
- 데이터 구조: 비트 배열
- 확률적 데이터 구조로, 정확도가 낮지만 메모리 사용량이 매우 적음
- 데이터 추가와 삭제가 모두 가능
- 정확도는 약 95% 수준
- 사용 사례:
- 웹 페이지 방문자 수 추정
- 광고 클릭 수 추정
- 트래픽 분석
- 요약하면, BloomFilter는 집합 멤버십 테스트에 사용되며, HyperLogLog는 중복 제거 후 집합의 크기를 추정하는 데 사용된다. 두 데이터 구조 모두 확률적이며, 메모리 사용량이 적다는 장점이 있다.
3. 집합 멤버십 테스트
- 집합 멤버십 테스트는 주어진 원소가 특정 집합에 속하는지 여부를 확인하는 연산이다. 이를 통해 특정 집합에 특정 원소가 포함되어 있는지를 판단할 수 있다.
- 예를 들어, 집합 A = {1, 2, 3, 4, 5}가 있다고 가정한다. 이때 다음과 같은 집합 멤버십 테스트를 수행할 수 있다:
- 3 ∈ A (true)
- 6 ∈ A (false)
- 이처럼 집합 멤버십 테스트를 통해 특정 원소가 집합에 포함되어 있는지 여부를 확인할 수 있다. 이는 데이터 구조와 알고리즘 설계 시 유용하게 활용될 수 있다.
2. Redis 특수 명령어
1) 데이터 만료(Expiration)
- Expiration : 특정 키에 대한 유효 기간을 설정
- EXPIRE key seconds: 지정한 키에 대해 초 단위의 유효 기간을 설정
- PEXPIRE key milliseconds: 지정한 키에 대해 밀리초 단위의 유효 기간을 설정
- TTL(Time To Live) : 데이터가 유효한 시간(초 단위)
- TTL key: 지정한 키의 남은 유효 기간(초)을 반환
- PTTL key: 지정한 키의 남은 유효 기간(밀리초)을 반환
- 특징 :
- 데이터 조회 요청시에 만료된 데이터는 조회되지 않음
- 데이터가 만료되자마자 삭제하지 않고, 만료로 표시했다가 백그라운드에서 주기적으로 삭제 됨
- PERSIST : 특정 키의 유효 기간을 제거
- PERSIST key: 지정한 키의 유효 기간을 영구적으로 설정
- 실습 코드 :
$ SET greeting hello
$ EXPIRE greeting 10
$ TTL greeting
$ GET greeting
$ SETEX greeting 10 hello
- 실습 결과 :
127.0.0.1:6379> SET greeting hello
OK
127.0.0.1:6379> TTL greeting
(integer) -1
127.0.0.1:6379> EXPIRE greeting 10
(integer) 1
127.0.0.1:6379> TTL greeting
(integer) 7
127.0.0.1:6379> TTL greeting
(integer) 5
127.0.0.1:6379> TTL greeting
(integer) 2
127.0.0.1:6379> GET greeting
(nil)
127.0.0.1:6379> SETEX greeting2 10 hi
OK
127.0.0.1:6379> GET greeting2
"hi"
127.0.0.1:6379> TTL greeting2
(integer) 5
127.0.0.1:6379> TTL greeting2
(integer) 3
127.0.0.1:6379> TTL greeting2
(integer) 2
127.0.0.1:6379> TTL greeting2
(integer) -2
127.0.0.1:6379> GET greeting2
(nil)
127.0.0.1:6379>
2) Set NX/XX
- NX 해당 Key가 존재하지 않는 경우에만 SET
- 키가 존재하는 경우에만 값을 설정
- 키가 존재하지 않으면 값을 설정하지 않음
- 이 옵션은 기존 값을 업데이트하는 경우에 유용함
- XX 해당 Key가 이미 존재하는 경우에만 SET
- 키가 존재하지 않는 경우에만 값을 설정
- 키가 이미 존재하면 값을 설정하지 않음
- 이 옵션은 원자적 작업을 보장하므로, 여러 클라이언트가 동시에 작업할 때 유용함
- Null Reply SET이 동작하지 않은 경우 (nil) 응답
- 실습 코드 :
$ SET greeting hello NX
$ SET greeting hello XX
- 실습 결과 :
127.0.0.1:6379> SET greeting hello NX
OK
127.0.0.1:6379> GET greeting
"hello"
127.0.0.1:6379> SET greeting hello XX
OK
127.0.0.1:6379> GET greeting
"hello"
127.0.0.1:6379> SET invalid abcd XX
(nil)
127.0.0.1:6379> SET greeting hello NX
(nil)
3) Pub/Sub
- Publisher와 Subscriber가 서로 알지 못해도 통신이 가능하도록 decoupling 된 패턴
- Publisher는 Subscriber에게 직접 메시지를 보내지 않고, Channel에 Publish
- Subscriber는 관심이 있는 Channel을 필요에 따라 Subscribe하며 메시지 수신
- Subscriber의 기능이 변경되어도 Publisher는 이를 신경쓰지 않아도 되고 Subscriber가 필요에 따라 채널을 조절하면 된다.
- Stream과 다른점 : 발행된 메시지가 보관되는 Stream과 달리 Pub/Sub은 fire/forget 매커니즘이 적용되어 있어서 구독전에 이미 발행된 메시지는 받을 수 없다. 즉 Subscribe 하지 않을 때 발행된 메시지는 수신 불가하다.

- 퍼블리셔(Publisher): 메시지를 생성하고 메시징 시스템에 게시하는 역할을 합니다. 퍼블리셔는 메시지를 특정 주제(topic)에 게시합니다.
- 컨슈머(Consumer): 퍼블리셔가 게시한 메시지를 구독하고 처리하는 역할을 합니다. 컨슈머는 자신이 관심있는 주제의 메시지를 구독합니다.
- 섭스크라이버(Subscriber): 컨슈머가 특정 주제의 메시지를 구독하는 것을 의미합니다. 컨슈머는 하나 이상의 주제를 구독할 수 있습니다.
- 실습 코드 :
- Consumer 명령어 :
$ SUBSCRIBE ch:order ch:payment
- Publisher 명령어 :
$ PUBLISH ch:order new-order
$ PUBLISH ch:payment new-payment
- 실습 결과 :

4) Pipeline
- 다수의 commands를 한 번에 요청하여 네트워크 성능을 향상 시키는 기술
- Round-Trip Times 최소화
- 대부분의 클라이언트 라이브러리에서 지원


1. Pipeline 시작하기:
- 대부분의 Redis 클라이언트 라이브러리에서는 Pipeline 모드를 시작하는 별도의 메서드를 제공한다.
- 예를 들어 Python의 redis 라이브러리에서는 pipeline() 메서드를 사용한다.
2. 명령 추가하기:
- Pipeline 모드에서는 일반적인 Redis 명령을 실행하는 것과 동일한 방식으로 명령을 추가할 수 있다.
- 예를 들어 set(), get(), incr() 등의 메서드를 호출하여 명령을 추가할 수 있다.
3. Pipeline 실행하기:
- 모든 명령을 추가한 후에는 Pipeline을 실행하여 서버에 전송해야 한다.
- 대부분의 Redis 클라이언트 라이브러리에서는 execute() 메서드를 제공한다.
4. 결과 확인하기:
- execute() 메서드를 호출하면 Redis 서버로부터 받은 응답 결과가 반환된다.
- 이 결과를 리스트 형태로 확인할 수 있다.
- Python의 redis 라이브러리에서 Pipeline을 사용하는 코드
import redis
# Redis 클라이언트 생성
r = redis.Redis()
# Pipeline 시작
with r.pipeline() as pipe:
# 명령 추가
pipe.set('key1', 'value1')
pipe.get('key1')
pipe.incr('counter')
# Pipeline 실행
results = pipe.execute()
# 결과 확인
print(results) # [True, b'value1', 1]
5) Transaction
- 다수의 명령을 하나의 트랜잭션으로 처리 -> 원자성(Atomicity) 보장
- 중간에 에러가 발생하면 모든 작업 Rollback
- 하나의 트랜잭션이 처리되는 동안 다른 클라이언트의 요청이 중간에 끼어들 수 없음
- Atomicity(원자성) : All or Nothing / 모든 작업이 적용되거나 하나도 적용되지 않는 것
- Pipeline과 비교 :
- Pipeline은 네트워크 퍼포먼스 향상을 위해 여러개의 명령어를 한 번에 요청
- Transcation은 작업의 원자성을 보장하기 위해 다수의 명령을 하나처럼 처리하는 기술
- Pipeline과 Transaction을 동시에 사용 가능
- 명령어 :
- MULTI : Transaction 시작을 알리는 명령어
- EXEC :
- Transaction 내의 명령어들을 실행하는 명령어
- Transaction 내의 모든 명령어가 성공적으로 실행되면 EXEC 명령어가 실행, 그렇지 않으면 Transaction이 취소됨
redis> MULTI
OK
redis> SET key1 value1
QUEUED
redis> GET key1
QUEUED
redis> EXEC
1) OK
2) "value1"
- DISCARD : 현재 진행 중인 Transaction을 취소하는 명령어
- WATCH :
- 특정 키에 대한 Watch를 설정하는 명령어
- 해당 키의 값이 변경되면 EXEC 명령어가 실패함
redis> WATCH key1 key2
OK
redis> MULTI
OK
redis> INCR key1
QUEUED
redis> INCR key2
QUEUED
redis> EXEC
1) (integer) 1
2) (integer) 1
- UNWATCH : 현재 설정된 Watch를 해제하는 명령어
- 실습 코드 :
$ MULTI
$ INCR foo
$ DISCARD
$ EXEC
- 실습 결과 :
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR foo
QUEUED
127.0.0.1:6379> DISCARD
OK
127.0.0.1:6379> GET foo
(nil)
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR foo
QUEUED
127.0.0.1:6379> EXEC
1) (integer) 1
127.0.0.1:6379> GET foo
"1"
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR foo
QUEUED
127.0.0.1:6379> INCR foo2
QUEUED
127.0.0.1:6379> DISCARD
OK
127.0.0.1:6379> GET foo
"1"
127.0.0.1:6379> GET foo2
(nil)
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR foo
QUEUED
127.0.0.1:6379> INCR foo2
QUEUED
127.0.0.1:6379> EXEC
1) (integer) 2
2) (integer) 1
127.0.0.1:6379> GET foo
"2"
127.0.0.1:6379> GET foo2
"1"
3. 데이터 타입 활용
1) String - One Time Password(임시 비밀번호)
- OTP / One-Time Password : 인증을 위해 사용되는 임시 비밀번호(e.g. 6자리 랜덤 숫자)

2) String - Distributed Lock(분산 락)
- Distributed Lock : 분산 환경의 다수의 프로세스에서 동일한 자원에 접근할 때, 동시성 문제 해결

3) String - Fixed Window Rate Limiter(비율 계산기)
- Rate Limiter : 시스템 안정성/보안을 위해 요청의 수를 제한하는 기술
- IP-Based, User-Based, Application-Based, etc.
- Fixed-window Rate Limiting 고정된 시간(e.g. 1분) 안에 요청 수를 제한하는 방법

4) List - SNS Activity Feed(소셜 네트워크 활동 피드)
- Activity Feed : 사용자 또는 시스템과 관련된 활동이나 업데이트를 시간순으로 정렬하여 보여주는 기능
- Fan-Out : 단일 데이터를 한 소스에서 여러 목적지로 동시에 전달하는 메시징 패턴
- 각 사용자는 자신의 feed list를 가지고 있다. user1이 post를 올리면, 관심이 있을 사용자 user2, user3을 식별하고 해당 사용자의 activity feed의 끝에 순서대로 feed를 저장한다. 관심있는 사용자들은 activity feed를 조회하면 시간 순서대로 정렬된 feed를 볼 수 있다. 서버는 정해진 최신 feed 수가 정해져 있다면 끝에서 해당 수만큼만 조회하여 전송할 수 있다.

5) Set - Shopping Cart(장바구니)
- Shopping Cart : 사용자가 구매를 원하는 상품을 임시로 모아두는 가상의 공간
- 특징 : 수시로 변경이 발생할 수 있고, 실제 구매로 이어지지 않을 수도 있다
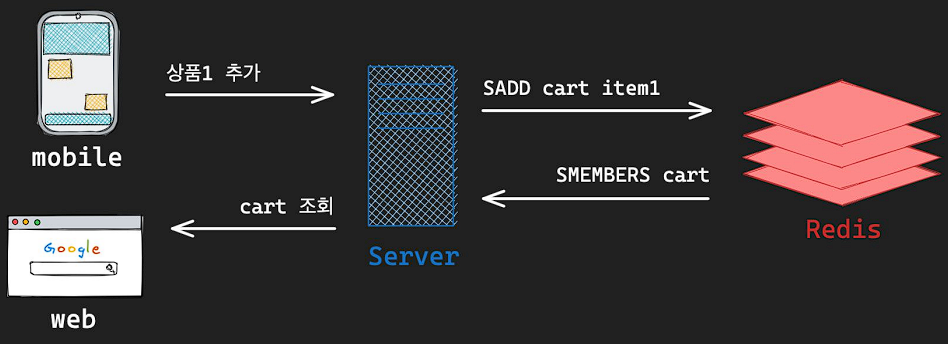
6) Hash - Login Session(로그인 세션)
- Login Session : 사용자의 로그인 상태를 유지하기 위한 기술
- 동시 로그인 제한 : 로그인시 세션의 개수를 제한하여, 동시에 로그인 가능한 디바이스 개수 제한

7) Sorted Set - Sliding Window Rate Limiter(비율 계산기)
- Sliding Window Rate Limiter : 시간에 따라 Window를 이동시켜 동적으로 요청수를 조절하는 기술
- Fixed Window와 비교 : Fixed Window는 window 시간마다 허용량이 초기화 되지만, Sliding Window는 시간이 경과함에 따라 window가 같이 움직인다.
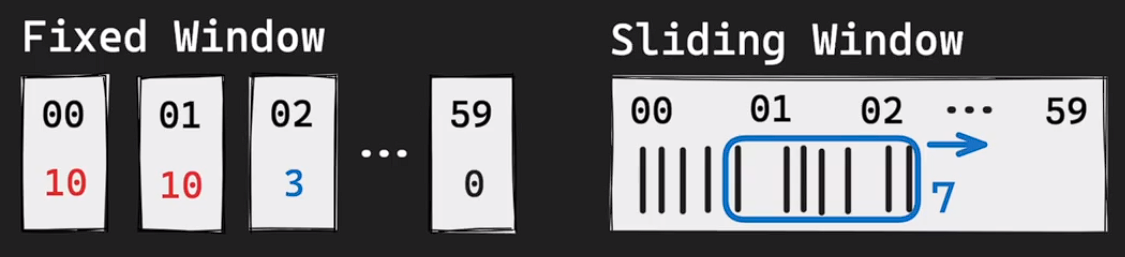

- unix time을 사용한다. 현재까지의 sliding window를 세가 위해서는 현재 시간(1693494130)에서 60초를 뺀 시간( 1693494070)에 해당하는 score에 해당하는 멤버를 sorted에서 제거한다. 이후 zcard 명령어를 통해 남은 데이터의 유니크한 값들을 계산하면 현재 시간으로 부터 60초 전까지의 요청 횟수를 확인할 수 있다.
8) Geospatial - Geofencing(반경 탐색)
- Geofencing : 위치를 활용하여 지도 상의 가상의 경계 또는 지리적 영역을 정의하는 기술

- 명령어 : 강남역 인근 500m 내 햄버거 가계 위치 찾기
- 위치값 저장 :
GEOADD gang-nam:burgers
127.025705 37.501272 five-guys
127.025699 37.502775 shake-shack
127.028747 37.498668 mc-donalds
127.027531 37.498847 burger-king
- 범위 내 가계 찾기 :
GEORADIUS gang-nam:burgers
127.027583 37.497928 0.5 km
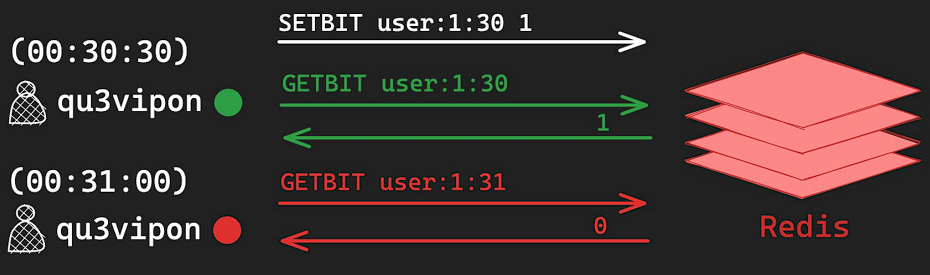
9) Bitmap - User Online Status(온라인 상태 표시)
- Online Status : 사용자의 현재 상태를 표시하는 기능
- 특징 : 실시간성을 완벽히 보장하지는 않는다. 수시로 변경되는 값이다.
10) HyperLogLog - Visitors Count(방문자 수 계산)
- Visitors Count Approximation :
- 방문자 수(또는 특정 횟수)를 대략적으로 추정하는 경우
- 정확한 횟수를 셀 필요 없이 대략적인 어림치만 알고자 하는 경우

- 명령어 :
- 사용자 정보 + 시간 : 초당 최대 1번만 중복 카운팅이 된다.
PFADD today:users
user:1:1693494070
user:1:1693494071
user:2:1693494071
- 카디널리티 추정
PFCOUNT today:users
11) BloomFilter - Unique Events(중복 이벤트 제거)
- Unique Events : 동일 요청이 중복으로 처리되지 않기 위해 빠르게 해당 item이 중복인지 확인하는 방법
- 클라이언트에서 발생하는 이벤트를 수집하는 서버가 있다고 할 때, 클라이언트의 실수로 중복된 이벤트를 여러번 요청할 수 있다. 이벤트 수집 서버는 이럴때를 대비하여 중복데이터를 제거하는 기능을 가지고 있어야 한다. 이때 사용할 수 있다.
- 데이터 추가시 :

- 데이터 추가시 : 추가시 존재한다고 나온다면? false positive일 수 있기 때문에 원본 데이터 소스를 한번 더 조회하고 데이터를 처리한다.

4. Redis 사용시 주의사항
1) O(N) 명령어
- O(N) 명령어 : 대부분의 명령어는 O(1) 시간복잡도를 갖지만, 일부 명령어의 경우 O(N)의 시간복잡도를 가진다.
- 주의사항 :
- Redis는 Single Thread로 명령어를 순차적으로 수행하기 때문에,오래 걸리는 O(N) 명령어 수행시, 전체적인 어플리케이션 성능 저하 발생
- 대표적인 O(N) 명령어 예시 :
- KEYS : keys * -> 모든 키 조회
- 지정된 패턴과 일치하는 모든 키 key 조회
- Production 환경에서 절대 사용 금지 -> SCAN 명령어로 대체
- SMEMBERS : Set의 모든 member 반환(N = Set Cardinality), 카디널리티가 높을 수록 동작이 오래 거린다.
- 한개의 set에 만개 이상의 아이템을 추가하지 않아야 한다.
- HGETALL : Hash의 모든 field 반환(N = Size of Hash)
- SORT : List, Set, ZSet의 item 정렬하여 반환
- DEL :
- 삭제하는 key가 많으면 오랜 시간 차단될 위험이 있다.
- UNLINK을 사용하자 O(1) 명령어이다. 다른 스레드에서 삭제 작업을 수행할 때는 O(N)이다.
- 64개 이하에서는 del로 동작한다.
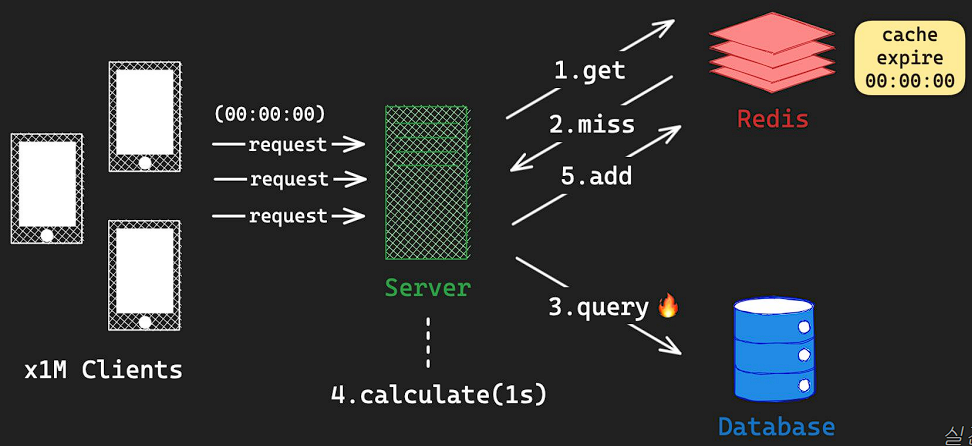
2) Thundering Herd Problem
- Thundering Herd : 병렬 요청이 공유 자원에 대해서 접근할 때, 급격한 과부하가 발생하는 문제
- 캐시의 만료로 발생할 수 있는 문제로, 캐시의 만료로 인해 수 많은 요청이 db로 연결되어 서버 과부하 문제가 발생하는 것이다. cronjob 등으로 주기적으로 캐시를 갱신하는 방법을 사용하여 해결 할 수 있다.
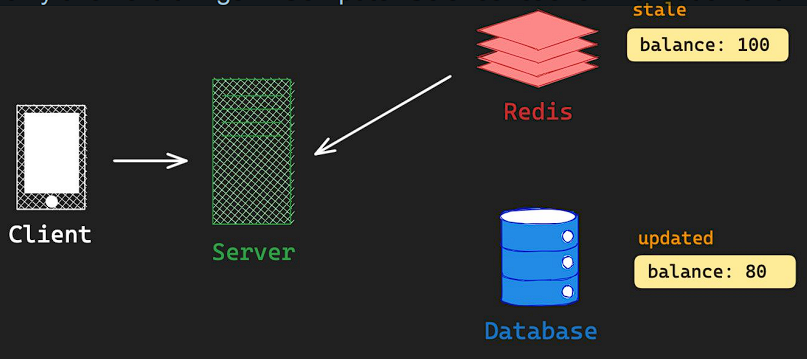
3) Stale Cache Invalidation
- Cache Invalidation : 캐시의 유효성이 손실되었거나 변경되었을 때, 캐시를 변경하거나 삭제하는 기술
- Two Hard Things : “There are only two hard things in Computer Science: cache invalidation and naming things”
- reference :
https://velog.io/@moonblue/%EC%8A%A4%ED%83%9DStack-%EA%B3%BC-%ED%81%90Queue
스택(Stack) 과 큐(Queue)
스택은 LIFO (Last In, First Out) 구조를 가진 자료구조로, 가장 마지막에 삽입된 데이터가 가장 먼저 삭제되는 구조 / 큐는 FIFO (First In, First Out) 구조를 가지며, 가장 먼저 삽입된 데이터가 가장 먼저
velog.io
https://velog.io/@sejinkim/Redis-KEYS-vs-SCAN
Redis KEYS vs SCAN
API의 Response를 캐시하는 기능을 개발하던 중 알게 된 Redis의 조회 명령어의 동작과 그 특성에 대해 설명합니다.
velog.io