[혼자 공부하는 머신러닝+딥러닝] 14강. 흑백 이미지 분류 방법과 비지도 학습, 군집 알고리즘 이해하기 - 지도 학습 샘플로 군집 알고리즘 학습
https://www.youtube.com/watch?v=u-G_sV7P_aA&list=PLJN246lAkhQjoU0C4v8FgtbjOIXxSs_4Q&index=15
-비지도 학습은 타겟 데이터가 없고 특성 데이터만 있다
- 사용자가 어떤 이미지를 입력할지 알 수 없기 때문에 정답을 사전에 정의할 수 없다.
- plt.imshow() : 넘파이 배열에 저장된 이미지를 그려준다. (image show)
- cmap : 이미지 색상 테마를 지정해준다. (color map)
- _r을 컬러 뒤에 붙이면 색을 반전시켜서 다시 그려준다.
plt.imshow(fruits[0], cmap='gray')
plt.show()
- plt.subplots
- subplot()와 subplots()가 있다. 둘다 같은 기능으로 한 화면에 여러개의 그래프를 그려주는 동작을 한다.
- subplot()는 추가되는 그래프의 화면마다 개별 선언을 해줘야 한다.
- subplots()는 한번에 추가되는 그래프들을 선언해 줄 수 있다.
- fig는 전체 화면에 대한 설정을 할 수 있고, axs는 각 세부 그래프에 대한 화면 설정을 할 수 있다.
fig, axs = plt.subplots(1, 2)
axs[0].imshow(fruits[100], cmap='gray_r')
axs[1].imshow(fruits[200], cmap='gray_r')
plt.show()
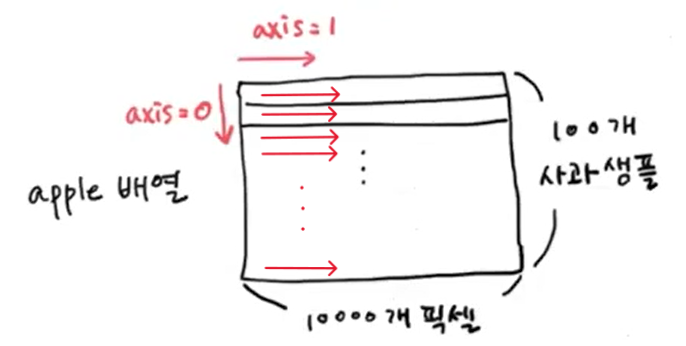
- 데이터 사용의 편리성을 위해 2차원 배열 데이터를 1차원 배열로 바꾼다.
- 현재 가로 100, 세로 100, 각 0~255의 범위 데이터를 가진 2차원 배열을 1차원 배열로 바꾼다.
- '-1은' 남은 차원을 알아서 할당시킨다. 행과 열 중 하나의 범위만 설정하면 -1 항목은 자동으로 충족되는 차원을 생성해준다.
apple = fruits[0:100].reshape(-1, 100*100)
pineapple = fruits[100:200].reshape(-1, 100*100)
banana = fruits[200:300].reshape(-1, 100*100)
print(apple.shape)
(100, 10000) #100개의 샘플과 각 샘플별 100*100의 값이 할당됨
- 샘플의 픽셀 평균값
- 각 샘플들마다 10,000개의 픽셀이 있는데, 이것을 평균 내보면 무언가 얻을 수 있지 않을까?
- axis = 1은 행(colomn)들을 선택하고 axis = 0은 열(row)을 선택한다.
- 사과, 파인애플, 바나나는 이미지 모양이 다 틀리니 아마 평균도 각각 틀릴거다?
- 과일 샘플 하나마다 평균을 내서 비교해본다
print(apple.mean(axis=1))
- 보기 쉽게 히스토 그램으로 확인하자
- alpha : 그래프 투명도 설정
- plt.legend() : 범례 첨부 설정
- 바나나는 확실히 구분이 되지만 파인애플이랑 사과는 구분이 어렵다.
plt.hist(np.mean(apple, axis=1), alpha=0.8)
plt.hist(np.mean(pineapple, axis=1), alpha=0.8)
plt.hist(np.mean(banana, axis=1), alpha=0.8)
plt.legend(['apple', 'pineapple', 'banana'])
plt.show()
- 픽셀의 샘플 평균값
- 축을 반대로 axis=0으로 해서 각각의 필셀마다 샘플의 평균값을 계산해보면 어떨까?
- 과일들의 모양이 다르니깐 각 위치별 픽셀들의 값이 다를 거라는 예상
- 각 다른 샘플들의 동일한 좌표위치에서의 값을 비교해본다

- 보기 쉽게 막대 그래프로 그려보자
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].bar(range(10000), np.mean(apple, axis=0))
axs[1].bar(range(10000), np.mean(pineapple, axis=0))
axs[2].bar(range(10000), np.mean(banana, axis=0))
plt.show()
- 사과는 뒤쪽으로 갈수록 값이 높아진다 (색이 어두워 진다)
- 파인애플은 비교적 고르게 높다
- 바나나는 중앙의 값이 높다.
- 각 과일들을 구분할 특징을 찾았다.
- 평균 이미지 활용하기
- 평균 이미지를 만들어 가장 비슷한 사진을 고르기
- 샘플 평균값 np.mean(apple, axis=0)을 100*100 크기의 2차원 배열로 만들어 이미지처럼 출력을 해보자
apple_mean = np.mean(apple, axis=0).reshape(100, 100)
pineapple_mean = np.mean(pineapple, axis=0).reshape(100, 100)
banana_mean = np.mean(banana, axis=0).reshape(100, 100)
# 100 * 100 이미지 형태로 배열을 바꾼다
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()
- 결과 이미지가 마치 모든 사진을 합쳐놓은 '대표 이미지'처럼 보여진다.
- 대표 이미지와 사용자가 올린 이미지를 비교하여 가장 차이가 적은 것을 선책할 수 있겠다.
- 평균 값과 가까운 사진 고르기
- 300개의 샘플 사진들 중 사과의 대표 이미지와 가장 비슷한 사진을 골라보자
- apple_mean : 사과의 대표 이미지 (사과 사진 100장에 대한 평균 이미지)
- .abs() : 절대값으로 계산해주는 함수 (absolute), 음수 값이 나오지 않아야 하는 경우에 사용
abs_diff = np.abs(fruits - apple_mean) # 300장의 사진들과 사과 대표이미지간의 차이값들(절대값)
# 3차원 배열 속 두번째, 세번째 축에 있는 차이값들을 모아서 평균낸다
abs_mean = np.mean(abs_diff, axis=(1,2))
print(abs_mean.shape) # 크기를 출력해보면 300개의 1차원 배열이 나온다
(300,)- 이렇게 구한 abs_mean(차이값들을 모아서 낸 평균값)이 가장 작은 샘플이 사과에 가장 가까운 이미지다.
- 처음 100개에 대해서 작은 순서대로 나열을 해보자.
- np.argsort() : 작은 값부터 순서대로 그 인덱스를 반환하는 함수
- 인덱스 중 (i * 10 + j)번째 것을 [i,j] 위치에 그림으로 그려보자
- 사과 대표이미지에 가장 가까운 것부터 100개의 그림이 그려진다.
apple_index = np.argsort(abs_mean)[:100] # 처음 100개만 argsort로 나열한다
fig, axs = plt.subplots(10, 10, figsize=(10,10)) # 10 by 10으로 총 100개의 칸
for i in range(__stop=10): # axs는 100칸 중에 i행 j열의 위치이다
for j in range(10): # i행 j열의 위치는 1차원으로 만들경우 (i * 10 + j)번째 값이다
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off') # 좌표축을 보고 싶지 않아서 설정한 값
plt.show()
- 바나나 학습
abs_diff = np.abs(fruits - banana_mean)
abs_mean = np.mean(abs_diff, axis=(1,2))
banana_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10,10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[banana_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
- 군집 (clustering)
- 사진들이 가지고 있는 픽셀값을 사용해 과일 사진을 모으는 작업을 해봤다.
- 이렇게 비슷한 샘플끼리 그룹으로 모으는 작업을 군집이라 하며 군집 알고리즘을 통해 묶은 그룹들을 클러스터(cluster) 라 한다
- 대표적인 비지도 학습이다
- 하지만 이번 강좌에서는 각 과일들의 평균값을 계산해서 찾은 것이기 때문에 사실 타깃이 존재했다
- 비지도 학습이라 할 수 없다. 실제 현장에서는 이렇게 샘플의 평균값들을 미리 구할 수 없다.
- 비지도 학습
- 타깃이 없을 경우 사용하는 머신러닝 알고리즘으로 사람이 가르쳐주지 않아도 알고리즘이 스스로 데이터 속에서 패턴을 찾아낸다.
- 대표적으로 군집과 차원축소가 있다.
- reference :
[혼공머신] 6-1. 군집 알고리즘
🍎농산물 시장까지 진출한 한빛마켓!🍌 이젠 고객이 필요한 과일 사진을 보내면, 그게 어떤 과일인지 구별하는 모델이 필요해졌다. 근데 손님들이 어떤 과일을 보낼지 알 수 없는데 훈련을 어
velog.io
https://webnautes.tistory.com/1392
NumPy 강좌 - np.sum 함수에서 axis 의미
NumPy 함수를 사용하다보면 axis 아규먼트를 사용하는 것이 있습니다. 어떤 의미일까 고민해보다가 적어봅니다. 최초 작성 2019. 11. 7 넘파이 모듈을 임포트 하고 크기 2 x 3 x 4인 넘파이 배열에 0~23까
webnautes.tistory.com
http://taewan.kim/post/numpy_sum_axis/
Numpy에서 np.sum 함수의 axis 이해
Numpy의 sum은 유용한 함수입니다. 그러나 처음 sum 함수를 사용할 때 axis 파라미터가 무엇을 의미하는지 혼동되는 것이 사살입니다. axis의 의미를 정리합니다.
taewan.kim
'데이터분석-머신러닝-AI > 강의 정리' 카테고리의 다른 글
| [혼자 공부하는 머신러닝+딥러닝] 16강. 주성분 분석: 차원 축소 알고리즘 PCA 모델 만들기 - 차원축소 PCA를 다른 알고리즘과 함께 사용하기 (1) | 2023.11.19 |
|---|---|
| [혼자 공부하는 머신러닝+딥러닝] 15강. k-평균 알고리즘 작동 방식을 이해하고 비지도 학습 모델 만들기 - 이미지 평균의 자동화 (1) | 2023.11.16 |
| [혼자 공부하는 머신러닝+딥러닝] 13강. 트리의 앙상블 - 다양한 앙상블 알고리즘 (1) | 2023.11.14 |
| [혼자 공부하는 머신러닝+딥러닝] 12강. 교차 검증과 그리드 서치 - (1) | 2023.11.13 |
| [혼자 공부하는 머신러닝+딥러닝] 11강. 로지스틱 회귀로 와인 분류하기 & 결정 트리 - 와인 분류하기 (1) | 2023.11.12 |
댓글